
Shopify is one of the largest Ruby on Rails codebases in existence. It has been worked on for over a decade by more than a thousand developers. It encapsulates a lot of diverse functionality from billing merchants, managing 3rd party developer apps, updating products, handling shipping and so on.
It was initially built as a monolith, meaning that all of these distinct functionalities were built into the same codebase with no boundaries between them. For many years this architecture worked for us, but eventually, we reached a point where the downsides of the monolith were outweighing the benefits. We had a choice to make about how to proceed.
Microservices surged in popularity in recent years and were touted as the end-all solution to all of the problems arising from monoliths. Yet our own collective experience told us that there is no one size fits all best solution , and microservices would bring their own set of challenges. We chose to evolve Shopify into a modular monolith, meaning that we would keep all of the code in one codebase, but ensure that boundaries were defined and respected between different components.
, and microservices would bring their own set of challenges. We chose to evolve Shopify into a modular monolith, meaning that we would keep all of the code in one codebase, but ensure that boundaries were defined and respected between different components.
Each software architecture has its own set of pros and cons, and a different solution will make sense for an app depending on what phase of its growth it is in. Going from monolith to modular monolith was the next logical step for us.
Monolithic architecture
According to Wikipedia, a monolith is a software system in which functionally distinguishable aspects are all interwoven, rather than containing architecturally separate components. What this meant for Shopify was that the code that handled calculating shipping rates lived alongside the code that handled checkouts, and there was very little stopping them from calling each other. Over time, this resulted in extremely high coupling between the code handling differing business processes.
Advantages of monolithic systems
Monolithic architecture is the easiest to implement. If no architecture is enforced, the result will likely be a monolith. This is especially true in Ruby on Rails, which lends itself nicely to building them due to the global availability of all code at an application level. Monolithic architecture can take an application very far since it’s easy to build and allows teams to move very quickly in the beginning to get their product in front of customers earlier.
Maintaining the entire codebase in one place and deploying your application to a single place has many advantages. You’ll only need to maintain one repository, and be able to easily search and find all functionality in one folder. It also means only having to maintain one test and deployment pipeline, which, depending on the complexity of your application, may avoid a lot of overhead. These pipelines can be expensive to create, customize, and maintain because it takes concerted effort to ensure consistency across them all. Since all of the code is deployed in one application, the data can all live in a single shared database. Whenever a piece of data is needed, it’s a simple database query to retrieve it.
Since monoliths are deployed to one place, only one set of infrastructure needs to be managed. Most Ruby applications come with a database, a web server, background jobs capabilities, and then perhaps other infrastructure components like Redis, Kafka, Elasticsearch and much more. Every additional set of infrastructure that is added, increases the amount of time you will have to spend with your DevOps hat on rather than your building hat. Additional infrastructure also increases the possible points of failure, decreasing your applications resiliency and security.
One of the most compelling benefits of choosing the monolithic architecture over multiple separate services is that you can call into different components directly, rather than needing to communicate over web service API’s. This means you don’t have to worry about API version management and backward compatibility, as well as potentially laggy calls.
Disadvantages of monolithic systems
However, if an application reaches a certain scale or the team building it reaches a certain scale, it will eventually outgrow monolithic architecture. This occurred at Shopify in 2016 and was evident by the constantly increasing challenge of building and testing new features. Specifically, a couple of things served as tripwires for us.
The application was extremely fragile with new code having unexpected repercussions. Making a seemingly innocuous change could trigger a cascade of unrelated test failures. For example, if the code that calculates our shipping rate called into the code that calculates tax rates, then making changes to how we calculate tax rates could affect the outcome of shipping rate calculations, but it might not be obvious why. This was a result of high coupling and a lack of boundaries, which also resulted in tests that were difficult to write, and very slow to run on CI.
Developing in Shopify required a lot of context to make seemingly simple changes. When new Shopifolk onboarded and got to know the codebase, the amount of information they needed to take in before becoming effective was massive. For example, a new developer who joined the shipping team should only need to understand the implementation of the shipping business logic before they can start building. However, the reality was that they would also need to understand how orders are created, how we process payments, and much more since everything was so intertwined. That’s too much knowledge for an individual to have to hold in their head just to ship their first feature. Complex monolithic applications result in steep learning curves.
All of the issues we experienced were a direct result of a lack of boundaries between distinct functionality in our code. It was clear that we needed to decrease the coupling between different domains, but the question was how.
You might also like: The Shopify GraphQL Learning Kit.
Microservice architecture
One solution that is very trendy in the industry is microservices. Microservices architecture is an approach to application development in which a large application is built as a suite of smaller services, deployed independently. While microservices would address the problems we experienced, they’d bring another whole suite of problems.
We’d have to maintain multiple different test and deployment pipelines and take on infrastructural overhead for each service while not always having access to the data we need when we need it. Since each service is deployed independently, communicating between services means crossing the network, which adds latency and decreases reliability with every call. Additionally, large refactors across multiple services can be tedious, requiring changes across all dependent services and coordinating deploys.
Modular monoliths
We wanted a solution that increased modularity without increasing the number of deployment units, allowing us to get the advantages of both monoliths and microservices without so many of the downsides.
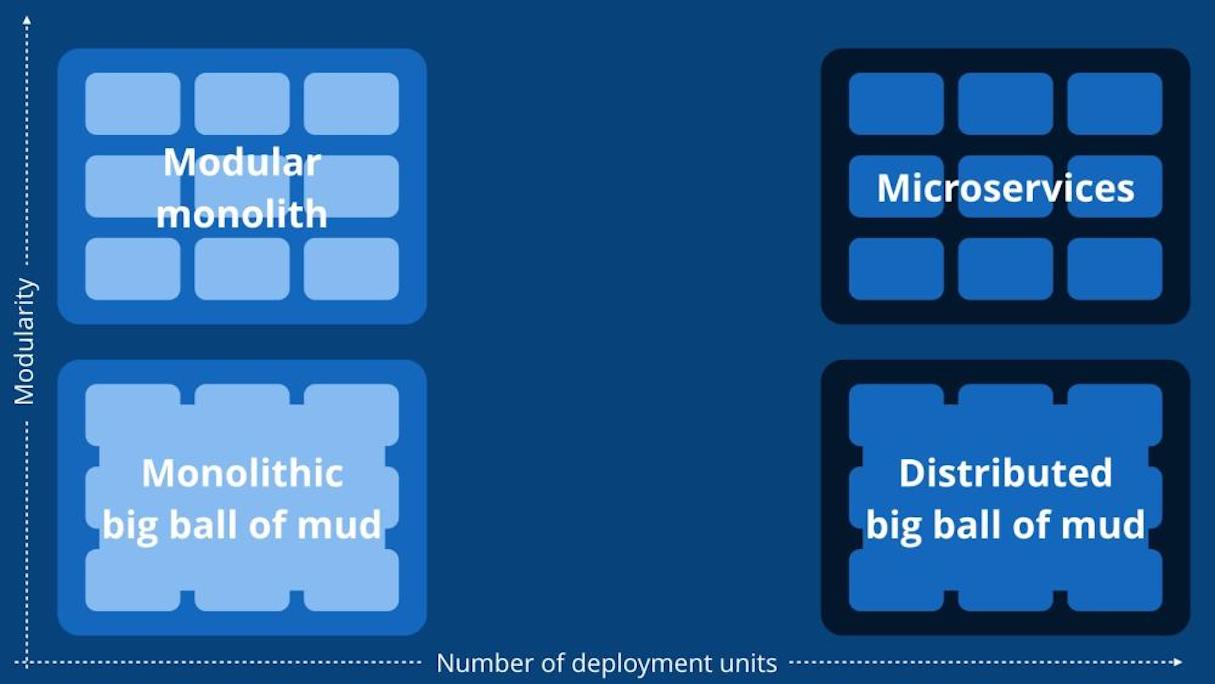
A modular monolith is a system where all of the code powers a single application and there are strictly enforced boundaries between different domains.
Shopify’s implementation of the modular monolith: Componentization
Once it was clear that we had outgrown the monolithic structure, and it was affecting developer productivity and happiness, a survey was sent out to all the developers working in our core system to identify the main pain points. We knew we had a problem, but we wanted to be data-informed when coming up with a solution, to ensure it was designed to actually solve the problem we had, not just the anecdotally reported one.
The results of that survey informed the decision to split up our codebase. In early 2017, a small but mighty team was put together to tackle this. The project was initially named “Break-Core-Up-Into-Multiple-Pieces”, and eventually evolved into “Componentization”.
You might also like: 3 Simple Steps for Setting Up a Local Shopify Theme Development Environment.
Code organization
The first issue they chose to address was code organization. At this time, our code was organized like a typical Rails application: by software concepts (models, views, controllers). The goal was to re-organize it by real-world concepts (like orders, shipping, inventory, and billing), in an attempt to make it easier to locate code, locate people who understand the code, and understand the individual pieces on their own. Each component would be structured as its own mini rails app, with the goal of eventually namespacing them as ruby modules. The hope was that this new organization would highlight areas that were unnecessarily coupled.

Coming up with the initial list of components involved a lot of research and input from stakeholders in each area of the company. We did this by listing every ruby class (around 6000 in total) in a massive spreadsheet and manually labeling which component it belongs in. Even though no code changed in this process, it still touched the entire codebase and was potentially very risky if done incorrectly. We achieved this move in one big bang PR built by automated scripts.
Since the changes introduced were just file moves, the failures that might occur would result from our code not knowing where to find object definitions, resulting in runtime errors. Our codebase is well tested, so by running our tests locally and in CI without failures, as well as running through as much functionality as possible locally and on staging, we were able to ensure that nothing was missed. We chose to do it all in one PR so we’d only disrupt all developers as little as possible. An unfortunate downside of this change is that we lost a lot of our Git history in Github when file moves were incorrectly tracked as deletions and creations rather than renames. We can still track the origins using the git -follow option which follows history across file moves, however, Github doesn’t understand the move.
Isolating dependencies
The next step was isolating dependencies, by decoupling business domains from one another. Each component defined a clean dedicated interface with domain boundaries expressed through a public API and took exclusive ownership of its associated data. While the team couldn’t achieve this for the whole Shopify codebase since it required experts from each business domain, they did define patterns and provide tools to complete the task.
We developed a tool called Wedge in-house, which tracks the progress of each component towards its goal of isolation. It highlights any violations of domain boundaries (when another component is accessed through anything but its publicly defined API), and data coupling across boundaries. To achieve this, we wrote a tool to hook into Ruby tracepoints during CI to get a full call graph. We then sort callers and callees by component, selecting only the calls that are across component boundaries, and sending them to Wedge. Along with these calls, we send along some additional data from code analysis, like ActiveRecord associations and inheritance. Wedge then determines which of those cross-component things (calls, associations, inheritance) are ok, and which are violating. Generally:
- Cross-component associations are always violating componentization
- Calls are ok only to things that are explicitly public
- Inheritance will be similar but isn’t yet fully implemented
Wedge then computes an overall score as well as lists violations per component.

As a next step, we will graph score trends over time, and display meaningful diffs so people can see why and when the score changed.
You might also like: The 20 Best Visual Studio Code Extensions for Front End Developers.
Enforcing boundaries
In the long term, we’d like to take this one step further and enforce these boundaries programmatically. This blog post by Dan Manges provides a detailed example of how one app team achieved boundary enforcement. While we are still researching the approach we want to take, the high-level plan is to have each component only load the other components that it has explicitly depended upon. This would result in runtime errors if it tried to access code in a component that it had not declared a dependency on. We could also trigger runtime errors or failing tests when components are accessed through anything other than their public API.
We’d also like to untangle the domain dependency graph by removing accidental and circular dependencies. Achieving complete isolation is an ongoing task, but it’s one that all developers at Shopify are invested in and we are already seeing some of the expected benefits. As an example, we had a legacy tax engine that was no longer adequate for the needs of our merchants. Before the efforts described in this post, it would have been an almost impossible task to swap out the old system for a new one. However, since we had put so much effort into isolating dependencies, we were able to swap out our tax engine for a completely new tax calculation system.
In conclusion, no architecture is often the best architecture in the early days of a system. This isn’t to say don’t implement good software practices, but don’t spend weeks and months attempting to architect a complex system that you don’t yet know. Martin Fowler’s Design Stamina Hypothesis does a great job of illustrating this idea, by explaining that in the early stages of most applications you can move very quickly with little design. It’s practical to trade off design quality for time to market. Once the speed at which you can add features and functionality begins to slow down, that’s when it’s time to invest in good design.
The best time to refactor and re-architect is as late as possible, as you are constantly learning more about your system and business domain as you build. Designing a complex system of microservices before you have domain expertise is a risky move that too many software projects fall into. According to Martin Fowler, “almost all the cases where I’ve heard of a system that was built as a microservice system from scratch, it has ended in serious trouble… you shouldn’t start a new project with microservices, even if you’re sure your application will be big enough to make it worthwhile”.
Good software architecture is a constantly evolving task and the correct solution for your app absolutely depends on what scale you’re operating at. Monoliths, modular monoliths, and Service Oriented Architecture fall along an evolutionary scale as your application increases in complexity. Each architecture will be appropriate for a different sized team/app and will be separated by periods of pain and suffering. When you do start experiencing many of the pain points highlighted in this article, that’s when you know you’ve outgrown the current solution and it’s time to move onto the next.
Thank you to Simon Brown for permission to post his monolith vs microservices image. For more information on Modular Monolith's please check out Simon's talk from GOTO18.
